
Git が分かりにくく感じる理由は、その背後でどのような処理が行われているのか、そのメカニズムがブラックボックスになっていることが原因だ。この記事では git add コマンドに焦点を絞って、その背後で何が行われているのかを明らかにしていきたいと思う。
![]()
git で管理するプロジェクトのディレクトリを作成する
まずは、プロジェクトのディレクトリを作成する。ここでは git-sample というディレクトリ名にした。作成したらそのディレクトリに移動しよう。
$ mkdir git-sample
$ cd git-sample/Git を初期化して、ローカルリポジトリを作成する
当然だが、この時点ではプロジェクトディレクトリには何も存在しない。
$ ls -a
./ ../このプロジェクトディレクトリを Git で管理するために、git init コマンドを実行して Git の初期化を行う。これによりプロジェクトディレクトリ git-sample の配下に .git という名前のディレクトリが作成される。
$ git init
Initialized empty Git repository in C:/git-sample/.git/
$ ls -a
./ ../ .git/「Initialized empty Git repository」とあるように、ここで作成された .git ディレクトリは(ローカル)リポジトリと呼ばれ、プロジェクトを管理するための様々なデータがここに保存されることになる。
$ ls .git -a
./ ../ config description HEAD hooks/ info/ objects/ refs/また、この時点でのリポジトリ .git のディレクトリ構成は次のようになっている。
.git/
├─ config
├─ description
├─ HEAD
├─ hooks/
│ ├─ applypatch-msg.sample
│ ...省略
│ └─ update.sample
├─ info/
│ └─ exclude
├─ objects/
│ ├─ info
│ └─ pack
└─ refs/
├─ heads
└─ tagsサンプルファイルを作成し、ステージに追加する
ステージへの追加によるリポジトリの変化
まず、サンプルとして「This is a sample file.」という中身をもつテキストファイルを sample.txt という名前で作成してみる。
$ echo 'This is a sample file.' > sample.txt
$ ls -a
./ ../ .git/ sample.txtこれを git add コマンドを用いてステージに追加してみよう。
$ git add sample.txt
$ ls .git -a
./ ../ config description HEAD hooks/ index info/ objects/ refs/ディレクトリ構成
.git/
├─ config
├─ description
├─ HEAD
├─ index <-- 追加された
├─ hooks/
│ ├─ applypatch-msg.sample
│ ...省略
│ └─ update.sample
├─ info/
│ └─ exclude
├─ objects/
│ ├─ 05/ <-- 追加された
│ │ └─ 303ef858aeeb01ca40590dd6fe65928096ee6c <-- 追加された
│ ├─ info
│ └─ pack
└─ refs/
├─ heads
└─ tagsつまり git add コマンドにより sample.txt をステージに追加したところ、次のような変化が起こった。
- リポジトリ .git の配下に index という名前のファイルが作成された。
- .git/objects ディレクトリの配下に「05」という名前のディレクトリが作成され、さらにその中には「303ef858aeeb01ca40590dd6fe65928096ee6c」という名前のファイルが作成された。
これらについて一つずつ理解してみよう。
.git/objects に追加される不思議な名前のディレクトリ・ファイル
まず、.git/objects ディレクトリの配下の「05」ディレクトリとその中に作成される「303ef858aeeb01ca40590dd6fe65928096ee6c」ファイルについて考えてみよう。これについては、こちらのサイトに解説があった。これらの不思議な名前の由来は以下のようになっている。
.git/objects ディレクトリに追加するデータのタイプ、ステージに追加したファイルのサイズ、ヌル文字(\u0000)からなる文字列を作成する。今回の sample.txt の場合、
- データのタイプは blob となる。blob とは塊(かたまり)の意味であり、Git では圧縮ファイルのことを指す。
- ステージに追加したファイル(sample.txt)のサイズは 23バイト
であるため、「’blob 23\u0000’」となる。これはヘッダーと呼ばれている。
そしてこのヘッダーと sample.txt の内容を結合したデータを SHA-1 というハッシュ関数により16進数40桁の値に変換する。
これをコマンドラインで実行させてみると次の結果を得る。
$ header='blob 23\u0000'
$ content='This is a sample file.\n'
$ str=$header$content
$ echo -ne $str | tr -d "\r" | sha1sum
05303ef858aeeb01ca40590dd6fe65928096ee6cこの結果の最初の2桁がディレクトリ名、残りの38桁がファイル名に使用されていることが分かる。
不思議な名前の由来は以上の通りだが、先ほどのサイトによるとファイルの中身はヘッダーと sample.txt の内容を結合したデータを圧縮したものになっているようだ。実際に解凍して中身を表示させてみると次のようになる。
$ openssl zlib -d < .git/objects/05/303ef858aeeb01ca40590dd6fe65928096ee6c
blob 23This is a sample file.以上をまとめると .git/objects ディレクトリの配下の「05」ディレクトリとその中に作成される「303ef858aeeb01ca40590dd6fe65928096ee6c」ファイルについては次のような意味がある。
- そのデータのタイプ(blob: 圧縮ファイル)とステージに追加したファイルのサイズを情報としてもつヘッダーが作成される。
- ヘッダーとステージに追加したファイルの内容を結合する。
- その結合を圧縮したものがデータの中身。
- その結合を SHA-1 でハッシュ化したものがディレクトリ名・ファイル名に付与される。
要するに、git add コマンドを使ってステージにファイルを追加すると、そのファイルの内容にヘッダーを付けて圧縮し、SHA-1 でハッシュ化した名前を与えたものが .git/objects 配下に追加されるということだ。
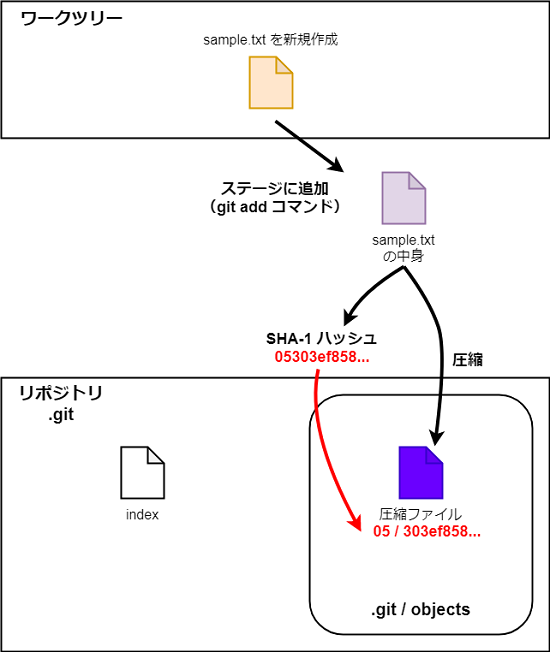
そしてここで重要なのは、ステージに追加したファイルの中身が同一であれば、ヘッダーを付与しても、その圧縮したもの、及び SHA-1 でハッシュ化した値は同一になるということだ。
したがって、ファイルの中身が同じであれば(ファイル名が異なっていたとしても)、git add コマンドにより追加で圧縮ファイルが作成されることはない。異なる内容のファイルが追加されたときのみ、圧縮ファイルが作成される。
リポジトリ .git の配下に作成される index ファイル
次に .git ディレクトリの配下に作成される index という名前のファイルが、どの様な意味を持つものであるかを見ていくことにする。
$ cat .git/index
▒▒e▒▒▒▒l.▒QP`H▒p.▒QP▒▒0>▒X▒▒▒@Y
sample.txt^c▒▒▒▒▒V{▒▒▒▒▒▒▒▒cat コマンドで index ファイルの内容を表示させてみると文字化けしている。こちらの説明によると、どうやらバイナリファイルらしい。xxd コマンドで16進数表示させると次のようになる。
$ xxd .git/index
00000000: 4449 5243 0000 0002 0000 0001 6048 a970 DIRC........`H.p
00000010: 2ea8 5150 6048 a970 2ea8 5150 0000 0000 ..QP`H.p..QP....
00000020: 0000 0000 0000 81a4 0000 0000 0000 0000 ................
00000030: 0000 0017 0530 3ef8 58ae eb01 ca40 590d .....0>.X....@Y.
00000040: d6fe 6592 8096 ee6c 000a 7361 6d70 6c65 ..e....l..sample
00000050: 2e74 7874 0000 0000 0000 0000 5e15 63c8 .txt........^.c.
00000060: cbd1 c905 9056 7bb6 97b0 f807 8796 bba5 .....V{.........こちらによると、最初の12バイト(ヘッダーと呼ばれる)の構成は
- 4バイトの署名 ‘D’, ‘I’, ‘R’, ‘C’(dircache の略)
- 4バイトのバージョン番号
- エントリーの個数(32ビット)
となっているらしい。1バイト(8ビット)は16進数の2桁に相当するので、xxd コマンドによる16進数表示の最初の12バイト(16進数24桁)を仕分けすると
44 49 52 43 --> ASCIIコードで D I R C
00 00 00 02 --> バージョン番号は「2」
00 00 00 01 --> エントリーの個数は1その後には index entry(つまり index に登録されたファイルの情報)が続くようだ。
- 32ビット ctime 秒、ファイルのメタデータが最後に変更された時刻
- 32ビット ctime ナノ秒端数
- 32ビットの mtime 秒、ファイルのデータが最後に変更された時刻
- 32ビット mtime ナノ秒端数
- 32ビットの dev(ファイルがあるデバイスの ID)
- 32ビットの ino(inode 番号)
- 32ビットの mode(アクセス保護モード)
- 4ビットの object type
1000 (regular file), 1010 (symbolic link), 1110 (gitlink) - 3ビット 使用しない
- 9ビットの unix permission
- 4ビットの object type
- 32ビットの uid(所有者のユーザー ID)
- 32ビットの gid(所有者のグループ ID)
- 32ビットの file-size(全体のサイズ (バイト単位) )
- Object name for the represented object(.git/objects に格納したデータの名前)
- 16ビットの flags フィールド
- エントリーのパス名(可変長)
- 1~8バイトの NUL(00)で埋める。
このフォーマットに従って16進数表示を仕分けすると(32ビットは16進数8桁に相当)
60 48 a9 70 --> タイムスタンプ 0x6048a970 --> 2021/03/10 20:11:44
2e a8 51 50 --> 0x2ea85150 --> 782782800 ナノ秒
60 48 a9 70 --> タイムスタンプ 0x6048a970 --> 2021/03/10 20:11:44
2e a8 51 50 --> 0x2ea85150 --> 782782800 ナノ秒
00 00 00 00 --> 0(ファイルがあるデバイスの ID)
00 00 00 00 --> 0(inode 番号)
00 00 --> ??? mode(アクセス保護モード)の上位4バイト(16ビット)
81 a4 --> 下位4バイト:2進数1000000110100100
--> 1000 (regular file), 000(未使用), 110100100(8進数644)
00 00 00 00 --> 0(所有者のユーザー ID)
00 00 00 00 --> 0(所有者のグループ ID)
00 00 00 17 --> 23 バイト(file-size)
05 30 3e f8 --> sample.txt の SHA-1 によるハッシュ値
58 ae eb 01 (05303ef858aeeb01ca40590dd6fe65928096ee6c)
ca 40 59 0d
d6 fe 65 92
80 96 ee 6c <-- ここまでハッシュ値
00 0a --> flags
73 61 --> s a (ASCIIコード)
6d 70 6c 65 m p l e
2e 74 78 74 . t x t
00 00 00 00 --> NUL(00) で埋める。
00 00 00 00これ以降にも数バイトの情報が残っているが、とりあえずここまでにしよう。ここまでの解析で index ファイルには、少なくとも以下の情報が書きこまれていることが分かった。
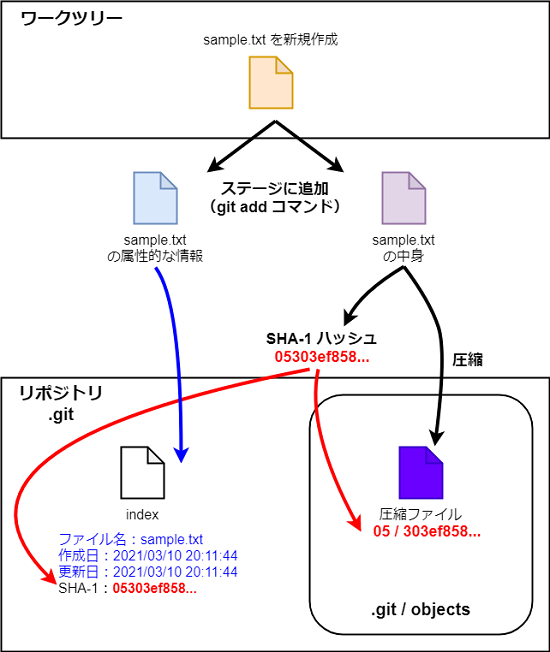
- git add コマンドで追加したファイルのパス名(sample.txt)
- そのファイルの SHA-1 ハッシュ値
- そのファイルの作成日や更新日時
git add コマンドが背後で行なっていること
以上のことから、git add コマンドが背後でどのようなことを行なっているかが分かってきた。つまり、git add コマンドによりステージにファイルを追加すると、
- ファイルの中身から作成されたハッシュ値を名前とする圧縮ファイルが作成され、.git/objects ディレクトリ配下に格納される。
- そして、index ファイルが作成される。この index にはステージに追加したファイルの名前や作成日など属性的な情報が記載され、またそのファイルの中身から作成されたハッシュ値も記載される。
要するに、ステージに追加したファイルの中身は圧縮されて(ハッシュ名が付与されて).git/objects ディレクトリに格納され、ファイルの属性的な情報は index に記載される。index にはハッシュ名も記載されるため、これを読むことにより圧縮された中身にアクセスすることができるようになっている。
以上が新規に作成した sample.txt ファイルを git add コマンドによりステージに登録したときの、その背後で行なわれている処理の詳細だ。
![]()

